First experiments with Vulkan
Update: I have been fiddling a lot more, and after some more investigation I made my mind up of a lot of things in this post, but I will still keep it since even though I still there are a lot of things wrong, I will not remove it, so I can still learn from it.
Introduction
In short, recently I have been experimenting with Vulkan, and my plan is to actually create some small posts with the things that I am discovering about the API itself, adding what I like or do not like about it. The issues that I found and how I handled them. (which of course might be a completely wrong approach), so this series of posts might be just me complaining about stuff that I might not be able to get up and running, or to share what I am learning, and, in the future, being able to check the progress.
Bear in mind, that I am not an expert or anything like that in Vulkan, (and that my explanations are not going to be the best out there), and this is the first time that I am actually learning a low-level API, so probably most of the stuff that I am about to write, might be the result of something that I just misunderstood. Even though, I want to have this post, for the record, if it can help anyone else, that is great, if someone can point out what I learned incorrectly that is great too!
First issues using vulkan
First contact and comparison
The first, and the biggest issue that I found, was the amount of code that is needed in order to actually boot up Vulkan, and wiring things up. (I know this is the same issue as everyone else, but it has a reason to be like this, right?)
I am not aiming for this to be a tutorial-like post, so I will not go into much detail. But I can say something that I have heard already, even though that its initial setup is huge, in comparison to any other API that I have worked with, it is pretty clear what needs to be done and at which stage things should be happening. Or at least. that is the feeling that I am having.
In comparison with OpenGL, where my personal feeling is that I am actually handling some levers on a huge state machine, and hoping for something to work the way I intended (which usually is not the case, and I found many issues with AMD cards that were not in my main NVidia). Vulkan is quite the opposite, (I believe that the same is applied to DX12), the user need to actually provide the pipeline status, and how everything is linked together, beforehand. And is assumed that it will do exactly as typed to the API. So, if something is provided wrongly, it will behave wrongly… Which is a nice thing, otherwise, will provide undefined behavior.
Going back to OpenGL, if you wanted to change your shader, in the middle of something, no one is preventing you from doing it, you can. You want to compile a shader too, you can do it, what about updating the blend state, or querying some uniforms out of a shader?, of course, you can. Just call the function that does that, and you are done!
Vulkan needs to know all of these stages beforehand, you want to render all your opaque geometry? ok, so you need to build a VkPipeline object and configure every single pipeline stage that pass is going to make use of. You want to render other stuff, but with a different shader, well, you guessed it. You need to build another VkPipeline with just another shaders set. And whenever you are done rendering your first pass, bind this new one to render more stuff with just another shader changed.
I strongly believe that there is a reason for this to be like this, otherwise, it would not make sense. And I do not have enough knowledge at the moment to know the very exact reason. (All I can guess is optimization since everything needs to be known beforehand, at both ends, drivers dev and graphics programmer dev)
I am skipping the Renderpass object, which VkPipeline needs to also know about, which I think is a topic just by itself, and something I believe unique to Vulkan?
Hierarchy and explanation of new things to me
My biggest problem was when learning how everything is actually linked together, I have found many pictures and posts about how everything is linked, and the top 2 that helped me out were these
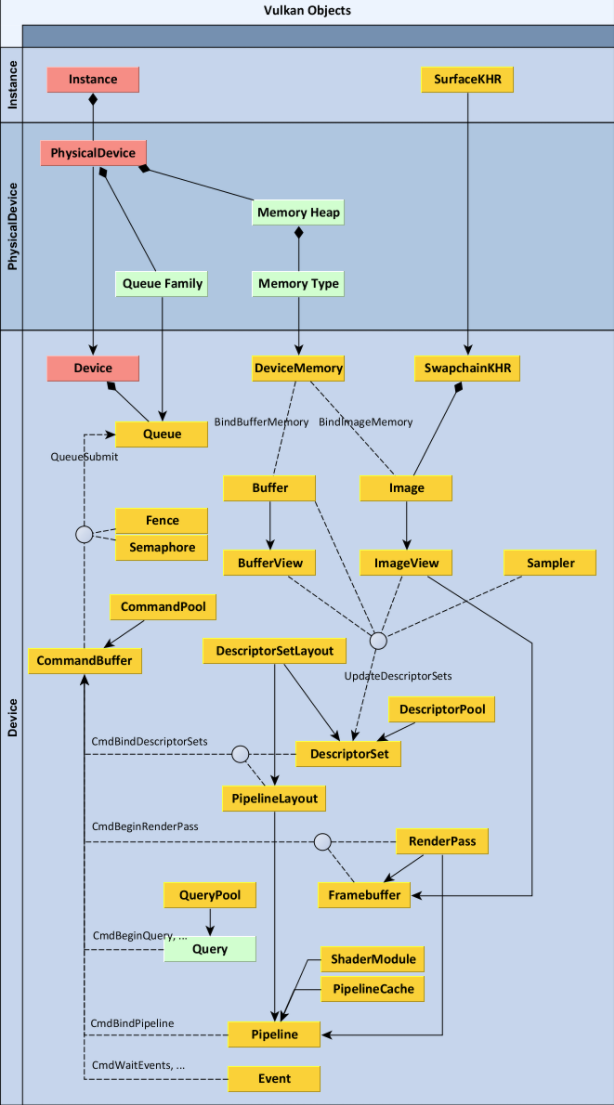
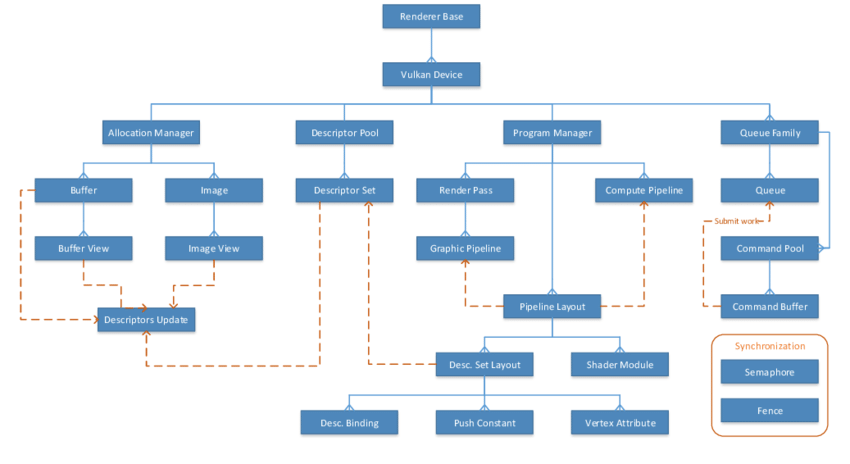
Why? I think that is just the fact, that one is actually showing the direct relation between resources, and the other one is adding the actual functions used to that hierarchy (although I think that this one is a bit more convoluted, is still a nice resource)
Starting by the fact that many of these actions are not happening straight away, (resource creation is not deferred, but copy commands, draw commands, dispatch commands are) they are recorded into command buffers that will be executed later. I usually think of them as a list of commands to execute, they got more stuff that you can add to them, but reduced to the smallest explanation, they seem to be just that.
At first, I naively thought, ok, this is cool, you can actually just append all of your operations into this, and you are done! Before typing any line of code, I started to read the documentation and some examples, and I found that you first need to query the available queues your device support, which obviously not every single card is going to support. But, you are at least guaranteed a minimum specification. So, according to my Nvidia GTX-1080, I got this:
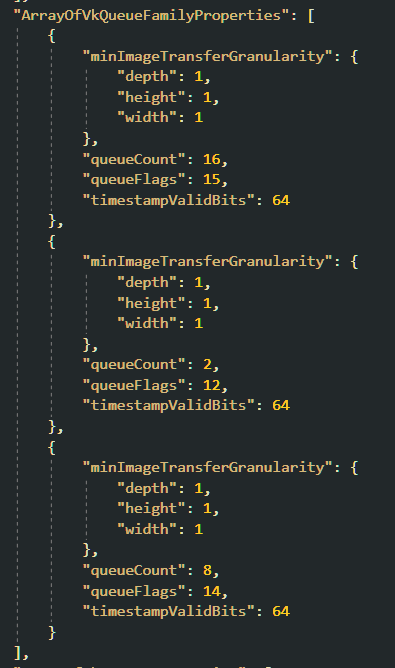
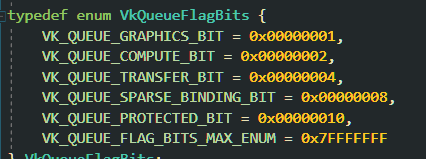
These values just show how many queues can be created that support each kind of operation, that was something new for me. I read that ideally, we want to use, let’s say, a dedicated transfer queue for large copy commands, but we can actually use any of the queues that are actually compatible with that operation… I have not tested it yet, I would assume that the best practice could be to find out if there is any specific queue that is dedicated to something and use it for that, and only that. So, do not do copy/dispatch commands in a graphics queue? But, before jumping to the next object inline, this already left a question open… each queue is executed independently unless synchronized via synchronization objects. So… you can have the number of queues you want (as long as do not request over the limit), but if you start using, let’s say a queue per thread and, split your transfer and compute operation into different queues, you will need to sync them. That is also a new concept for me
If you already got a queue, how do we use it? As it was said before, we use command buffers, which are created out of command pools, which need to know what type of queue they refer to, but not which queue specifically they are going to be working with, just its type. And then, each type that you want to execute a command, it will ask for a command buffer. And once you are done with it, you submit it and it will be executed.
Jumping to another object, we got the descriptor set layout, which, essentially is the description (layout) of how the shader resources are expected to be. This includes at which binding point, and which set, a given resource is expected to be. This is just the data layout, is not pointing to any actual resource, and it seems to be aiming for, creating as many actual resources that respect this layout, out of this object. The pipeline object needs to know about this (I assume that in order to be able to further optimize, knowing how the resources are laid out before doing anything?) and dealing with these classes behaves the similar way command buffer/command pools, we need to have a descriptor set pool in order to create descriptor sets using this layout object…
Directly related to the actual descriptor set, which this time, IT IS the actual resource in memory that we refer to since the pipeline needs to know about about the Descriptor set layout, and this object is created using that same layout, I assume that this is to be able to reuse multiple descriptors set layouts in the same pipeline. Or at least I am using them with that idea in mind.
Highlighting that in one image, is showing Vertex Attribute as a direct dependency of descriptor set layout, which I believe might be an issue, since the vertex attribute is set in the VkPipeline object itself (unless that there is a way to actually set it via Descriptor set or I am just misunderstanding that reference in the scheme, although might refer to a dynamic state that can be set in the pipeline, in that case, I did not say anything…)
Push constants seem to be a small buffer, of at least 128 bytes of data, that lives in the command buffer itself, allowing to quickly pass down some small amount of data to the shader now worrying about the actual descriptor set itself. Something I did not know before, and I think is pretty cool.
Then we got Buffer/Images, which at this point, behaves more or less the way I would expect, (after reading many samples, of course…) I will skip the actual VkDeviceMemory, since I consider that one to be a highly important one, which I prefer to work more with before actually talking about it. Since my small project is not making use of a lot of things, I want to actually test. Like, coherent memory vs non-coherent, is it worth using coherent memory for small data size? does it even matter if the data is small enough? at which point is better not to use it among many other questions…
In my mind, we got a buffer that is bound to an already allocated memory, and we then we create a view of the buffer we want to deal with, simple as that (there is obviously much more stuff going under the hood, but in a nutshell that is all). Images are the exact same thing, but they need more memory to fit all the extra information they need (this is to put it as simple as possible).
Then we got the big confusing object, or I think so, the actual Renderpass object, which I do not feel confident talking about it, yet. So I will say that is something similar to what descriptor set layout it is for descriptor set or pipeline layout it is for the pipeline. But in this case, it describes, does not know about any actual resource, only describes the texture attachments (color/depth) to the pipeline, and how they behave between surpasses. Which seems to be a way to describe a sequence of ‘passes’ and the dependency between them. (not the best description you might hear of…) I will talk about that once I feel confident enough about it.
The actual resource in memory is held by the Framebuffer object, which sounds confusing to me at first.
I know I missed a lot of stuff, but I wanted to just record what caught my attention the first time I saw it…
Also, almost every single of those objects is directly related to the pipeline, so I guess its safe to assume that many of those will be actually reused.
First issue after having something on screen
This might be a naive issue, but I wanted to share it, I am using GLM because I consider being a good math library, in the future I might try to implement my own, but this is not about math libraries. So going straight to my first ‘rendering’ issue.
I provided a set of Counter Clock Wise vertices, representing a triangle, which base was in the bottom…
And what did I get in the screen, a triangle that is inverted, the base was in the top.
I used renderdoc just to figure out what was going on, and I also saw many samples and people complaining about this specific issue, which, is not an actual issue, is just that I was expecting a different handedness. There are a couple of fixes for this, which, being completely honest, I do not like a bit.
I saw that after the quality of life update, the trick to flip the viewport is part of the core, so, yeah, one trick is to flip the viewport itself, which already is highlighting some issues to me (if we flip the viewport only, is something else going to be flipped? the input for example?)
The other option was to flip all your data, so it is the other way around, so, whenever it is flipped, it gets back to normal, which I do not like either
I also saw people suggesting to flip the Y in every vertex shader!
Then, as a test, I just created a coordinate systems gizmo-like and I found that this was behaving as a left-handed coordinate systems, which Y was pointing downwards, which I do not like
My solution might be one of the ugliest out there, I am pretty sure about that, but I ended up modifying the projection matrix, so it scales everything in the Y-axis by -1 and negating the input of the camera… This way, everything behaves as a right-handed Y up coordinate system, which I am way more comfortable working with
Ending…
I think this is pretty long already, I have not talked about some important topics, I would like to talk, and about the ones I have, I am pretty sure I have not explained myself as good as I could, but that is another skill I want to build along with this posts…
I do not want this to be much longer, so I will finish it here. This was the first contact point I had with Vulkan, about 2-3 months ago, and I wanted to record it, so I can actually check how this small project evolves. My current plan is to develop a small toy engine I am comfortable using to learn about different rendering techniques as well as learning about Vulkan, and once is ready to be presented to the world (not how it is right now, with a massive amount of TODO’s and things to learn how to use), make it public in Github
Right now is my main weekend’s project, along with some other experiments I am also researching, surrounding this Toy-engine idea
One last picture, what currently is happening, a pretty damm simple thing, but, unless, showing progress